AIが「答える」から「やる」に変わった月——2026年3月のAIリリースを振り返る
itpicks_admin
IT Picks

2026年3月10日、GoogleがAI開発者向けに大きなリリースを出しました。
Gemini Embedding 2——テキスト・画像・動画・音声・PDFという5種類のメディアを、初めて1つのベクトル空間に統合して扱える埋め込みモデルです。
「埋め込みモデルって何?」というところから、何が変わるのかをひと通り整理します。
この記事はこんな人向けです:
AIが文章や画像を理解するとき、コンピューターは「数値のリスト(ベクトル)」に変換して処理します。この変換を行うのが埋め込みモデル(Embedding Model)です。
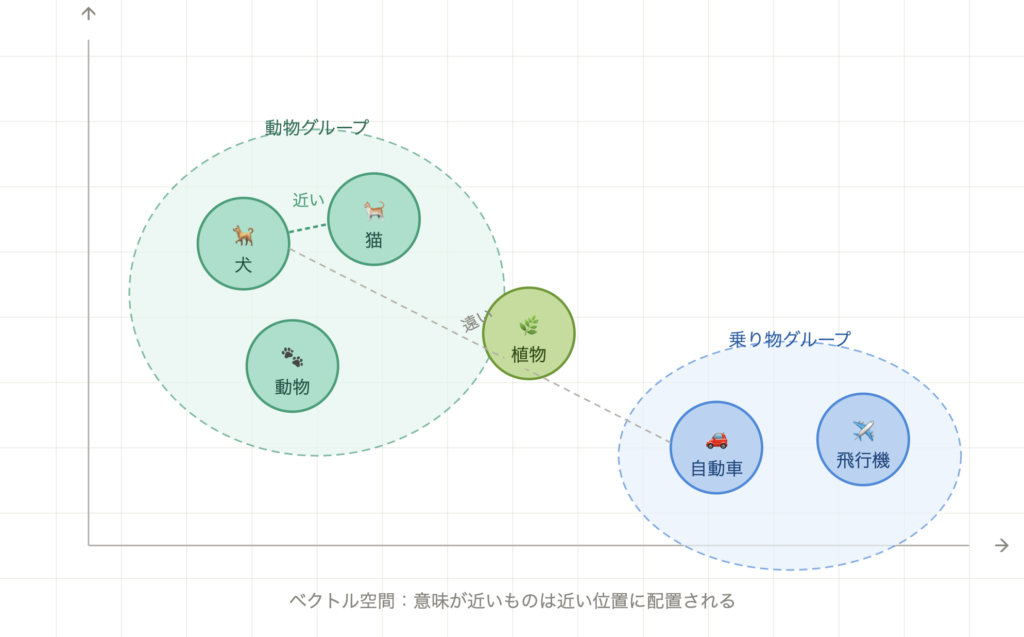
「意味が近いコンテンツは、ベクトル空間でも近い位置に配置される」という仕組みです。
たとえば「犬」と「猫」はどちらも動物なので、ベクトル空間で近い位置に配置されます。「犬」と「自動車」は遠い位置になります。この距離を使って「似ているコンテンツを探す(意味検索)」が実現できます。
RAG(Retrieval-Augmented Generation)でAIが社内文書を検索して回答するとき、この埋め込みモデルが「どの文書が質問に関係しているか」を判定しています。
Gemini Embedding 2は、テキスト・画像・動画・音声・ドキュメントを単一の統合された埋め込み空間にマッピングし、100以上の言語にわたって意味的な意図を捉える、Google初の完全マルチモーダル埋め込みモデルです。
これまでのGoogleの埋め込みモデル(gemini-embedding-001)はテキストのみに対応していました。Gemini Embedding 2は、5種類のメディアを同じ数学的空間に入れるという技術的な転換をもたらしています。
| gemini-embedding-001(旧) | Gemini Embedding 2(新) | |
|---|---|---|
| 対応メディア | テキストのみ | テキスト・画像・動画・音声・PDF |
| モデル名 | gemini-embedding-001 | gemini-embedding-2-preview |
| 最大トークン数 | 2,048 | 8,192 |
| ベクトル次元数 | 768 | 3,072(768・1,536にも調整可) |
| 多言語対応 | 対応 | 100言語以上 |
| 提供状況 | GA(正式版) | パブリックプレビュー |
最大の変化は「別々に処理していたものが、1つで済む」ことです。
従来のマルチモーダル検索システムを構築する場合、こんな複雑なパイプラインが必要でした。
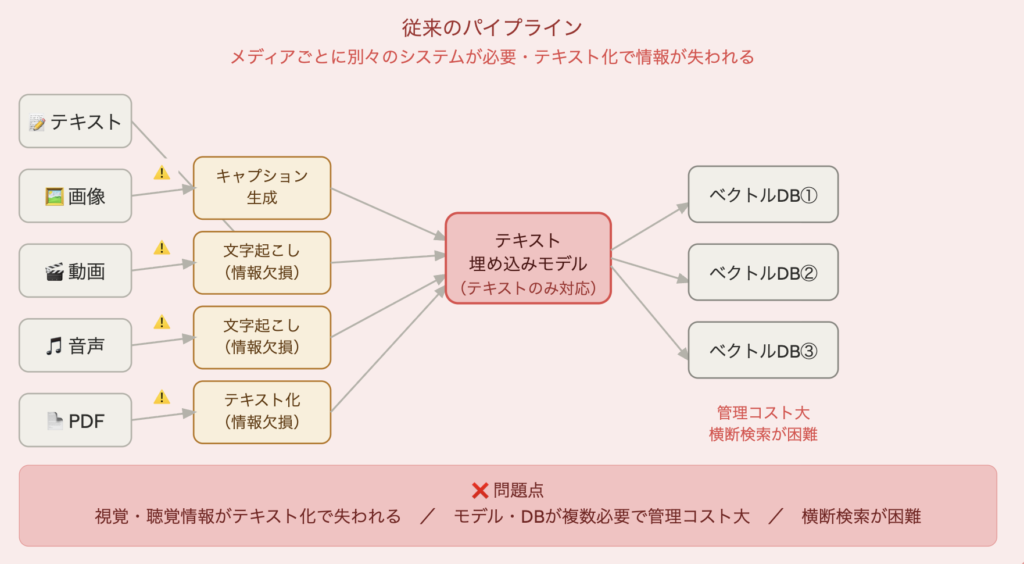
問題は、画像・動画・音声をいったんテキストに変換するため、視覚的・聴覚的な情報が失われることです。映像の色合い、音声のトーン、動作の流れ——こういった情報はテキスト化の段階で削ぎ落とされます。
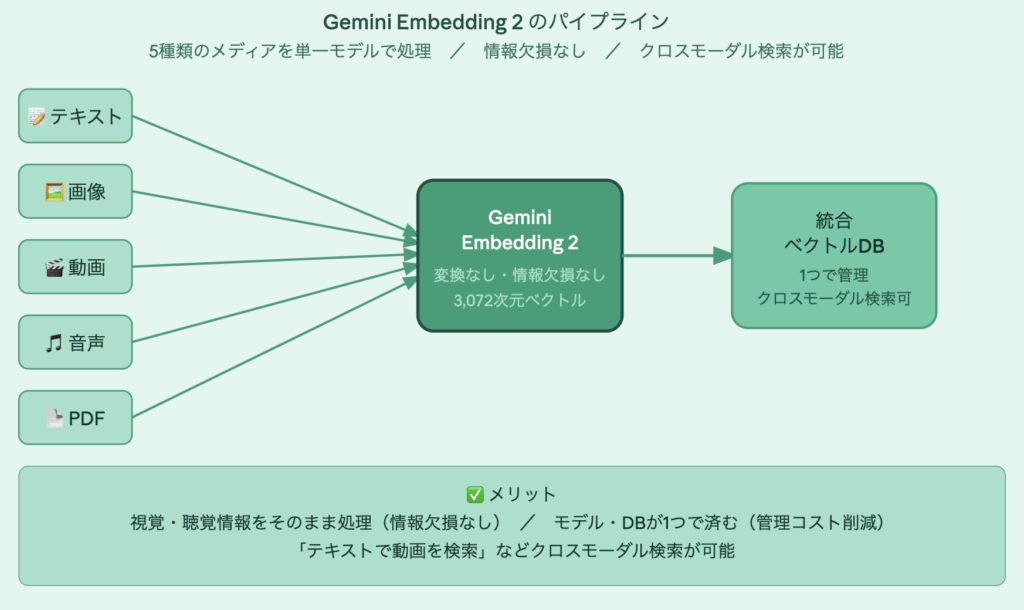
5種類のメディアを単一の3,072次元の空間にマッピングすることで、開発者はもはや画像検索とテキスト検索に別々のシステムを必要とせず、テキストクエリで動画の特定の瞬間や特定の音声に一致する画像を見つけるクロスモーダル検索ができるようになります。
各入力タイプの確認済みパラメータは以下の通りです。
| メディア | 最大入力量 | 対応フォーマット |
|---|---|---|
| テキスト | 8,192トークン/リクエスト | 100言語以上 |
| 画像 | 6枚/リクエスト | PNG・JPEG |
| 動画 | 128秒/リクエスト | MP4・MOV(H264/H265/AV1/VP9) |
| 音声 | 80秒/リクエスト | MP3・WAV |
| 6ページ/リクエスト | PDF(テキスト・視覚情報両方を処理) |
1リクエストあたりの合計最大入力は8,192トークンです。複数のメディアを混在させる場合はこの上限内に収める必要があります。
制限を超えるコンテンツの処理方法: 動画が128秒を超える場合・音声が80秒を超える場合は、チャンク(断片)に分割してそれぞれ埋め込みを生成し、後から統合する実装が必要です。
Gemini Embedding 2は「マトリョーシカ表現学習(MRL)」という技術を採用しており、最も重要な意味情報をベクトルの先頭の次元に詰め込むよう学習されています。
これはロシアの入れ子人形(マトリョーシカ)に例えられる技術です。外側の人形を開けると中に人形が入っているように、ベクトルの上位次元には下位次元の情報がすべて含まれています。
実用的な意味
| 次元数 | 用途 | ストレージ・速度 |
|---|---|---|
| 3,072(デフォルト) | 高精度が必要な本番環境(法務・医療など) | 最大 |
| 1,536 | バランス型(一般的なRAG・検索) | 半分 |
| 768 | 大規模データの高速検索・コスト重視 | 1/4 |
3,072次元のベクトルを768次元に圧縮しても、通常の埋め込みモデルのように精度が大幅に落ちません。ストレージコストと検索速度をトレードオフなしで調整できるのがMRLの強みです。
ベクトルDBのコストと速度で悩んでいる開発者には、ここが一番効いてくる機能です。
クロスモーダル検索とは、異なるメディア同士を横断して検索できることです。
具体例で説明します。
例①:テキストで動画を検索 製品の組み立て動画が100本ある状況で、「ネジを締めるシーン」とテキストで検索すると、関連する動画クリップが引っかかります。動画を文字起こしする必要はありません。
例②:画像で音声を検索 カスタマーサポートの音声記録5,000件と製品画像があるとき、特定の製品画像を渡して「この製品に関する問い合わせ音声」を検索できます。
例③:音声と画像を同時に渡して検索 「この画像のシーンで、この音声のような雰囲気のコンテンツを探して」という複合クエリが単一のリクエストで処理できます。
ビデオ対テキスト・テキスト対ビデオの検索タスクにおいて、ネイティブアーキテクチャによってテキストベースの文字起こしパイプラインに伴う性能低下を回避でき、動きと時間的データを統一された意味空間に正確にマッピングすることを実証しています。
社内の資料検索に画像・PDF・動画が混在している企業では、Gemini Embedding 2で単一のベクトルDBを構築できます。「先週の製品発表動画の中でCTOが話していた内容を教えて」という質問に、動画を文字起こしせずに直接答えられる仕組みが作れます。
商品画像・説明テキスト・レビュー音声・デモ動画を同一空間にマッピングすると、「この画像に近い商品」「このレビューのような評判の商品」という横断検索が実現できます。
Googleは法律専門家が訴訟の証拠開示プロセスで重要情報を見つける際の活用例を挙げており、Geminiのマルチモーダル埋め込みにより数百万件のレコードにわたる精度と再現率が向上し、画像・動画検索が強化されたことが示された。
YouTubeやオンライン講座など大量の動画を持つプラットフォームで、動画の内容を文字起こしせずにそのまま意味検索できるインデックスを構築できます。
| 項目 | 料金 |
|---|---|
| テキスト入力 | $0.20/100万トークン |
| 画像・動画・音声・PDF | 無料枠あり(詳細は公式ページ参照) |
| バッチAPI | 2026年3月時点で未提供(gemini-embedding-001は利用可) |
競合との料金比較
テキストのみの用途では、OpenAIのtext-embedding-3-small($0.02/100万トークン)と比べてGemini Embedding 2は約10倍高いです。テキスト検索だけで十分なシステムには、コスパの面でOpenAIが有利な場面もあります。
ただし、マルチモーダル対応が必要な場合、OpenAIは2026年3月時点でマルチモーダル埋め込みモデルを提供していません。マルチモーダルが必要かどうかが、選択の分かれ目です。
一部の顧客でレイテンシが最大70%削減されたという報告もあります。パイプラインのシンプル化によるインフラコスト削減まで含めると、トータルコストはケースバイケースで評価が必要です。
モデル名: gemini-embedding-2-preview
Gemini APIとVertex AIの両方で利用可能です。LangChain・LlamaIndex・Haystack・Weaviate・QDrant・ChromaDBなど主要ライブラリからも使えます。
テキスト埋め込みの基本的な呼び出し(Python)
import google.generativeai as genai
genai.configure(api_key="YOUR_API_KEY")
result = genai.embed_content(
model="models/gemini-embedding-2-preview",
content="Gemini Embedding 2のテスト",
output_dimensionality=3072 # 3072, 1536, 768 から選択
)
print(result['embedding']) # 3072次元のベクトルが返る
画像とテキストを混在させる場合
import PIL.Image
img = PIL.Image.open("product.jpg")
result = genai.embed_content(
model="models/gemini-embedding-2-preview",
content=[img, "この製品の説明文"] # 画像とテキストを同時に渡す
)
Colabのインタラクティブノートブックが公式から提供されているので、まずそちらで動作確認するのがおすすめです。
最重要:既存ベクトルデータとの互換性がない
gemini-embedding-001とgemini-embedding-2-previewの埋め込み空間は互換性がありません。モデルを切り替える場合、既存のすべてのデータを新モデルで再埋め込みする必要があります。異なるモデルで生成されたベクトル同士のコサイン類似度は意味を持ちません。
大規模なデータセットの再埋め込みにはコストと時間がかかります。
移行の進め方(推奨)
現時点ではGemini Embedding 2はパブリックプレビューであり、正式リリース(GA)までにベクトル空間が変更される可能性もゼロではありません。本番環境への全面移行はGAを待ってから判断するのが無難です。
| モデル | マルチモーダル対応 | テキスト料金 | 最大次元数 | 提供状況 |
|---|---|---|---|---|
| Gemini Embedding 2 | ◎(5種) | $0.20/1Mトークン | 3,072 | パブリックプレビュー |
| gemini-embedding-001 | ✕(テキストのみ) | — | 768 | GA |
| OpenAI text-embedding-3-large | ✕ | $0.13/1Mトークン | 3,072 | GA |
| OpenAI text-embedding-3-small | ✕ | $0.02/1Mトークン | 1,536 | GA |
| Amazon Nova 2 Multimodal | ○(一部) | — | — | GA |
テキスト検索のみのコストパフォーマンスではOpenAIが圧倒的に優位です。マルチモーダル対応が必要かどうかが、モデル選定の一番の軸になります。
「埋め込みモデル」はAIの中でも地味な存在で、生成AIほど話題になりません。ただ、RAGやセマンティック検索を使っている開発者にとっては、生成モデルと同じくらい重要な部品です。
Gemini Embedding 2が面白いのは、「モダリティの壁を取り除く」という一点に特化しているところです。
これまでのAIシステムは「テキストはテキストで、画像は画像で」という世界で動いていました。人間は「この写真はあの話に関係がある」と直感的に分かることを、AIは別々のシステムで処理してからテキストに変換して統合する、という回り道をしていました。Gemini Embedding 2はその回り道を短くします。
課題として、バッチAPIが未提供・パブリックプレビュー段階・既存ベクトルとの非互換という3点があります。大規模な本番環境への全面移行はGAを待つべきですが、無料枠を使った精度検証は今すぐ始める価値があります。
Gemini Embedding 2のポイントをまとめます。
gemini-embedding-2-previewマルチモーダルデータを持つ企業・開発者は、今すぐ無料枠で自社データの精度検証を始めることをおすすめします。GAリリース後に即座に移行判断ができる状態を作っておくのが最もリスクが低い進め方です。





